NaiveBayes
Algoritmo Naive Bayes
Introducción
Naive Bayes es un conjunto de algoritmos de clasificación probabilística basados en el teorema de Bayes, que se utiliza ampliamente en problemas de clasificación, particularmente en el análisis de texto y el filtrado de spam. La «naive» (ingenua) parte del nombre proviene de la suposición de que todas las características (o variables) son independientes entre sí, dado el valor de la clase.
Funcionamiento
El algoritmo Naive Bayes utiliza la siguiente fórmula basada en el teorema de Bayes:
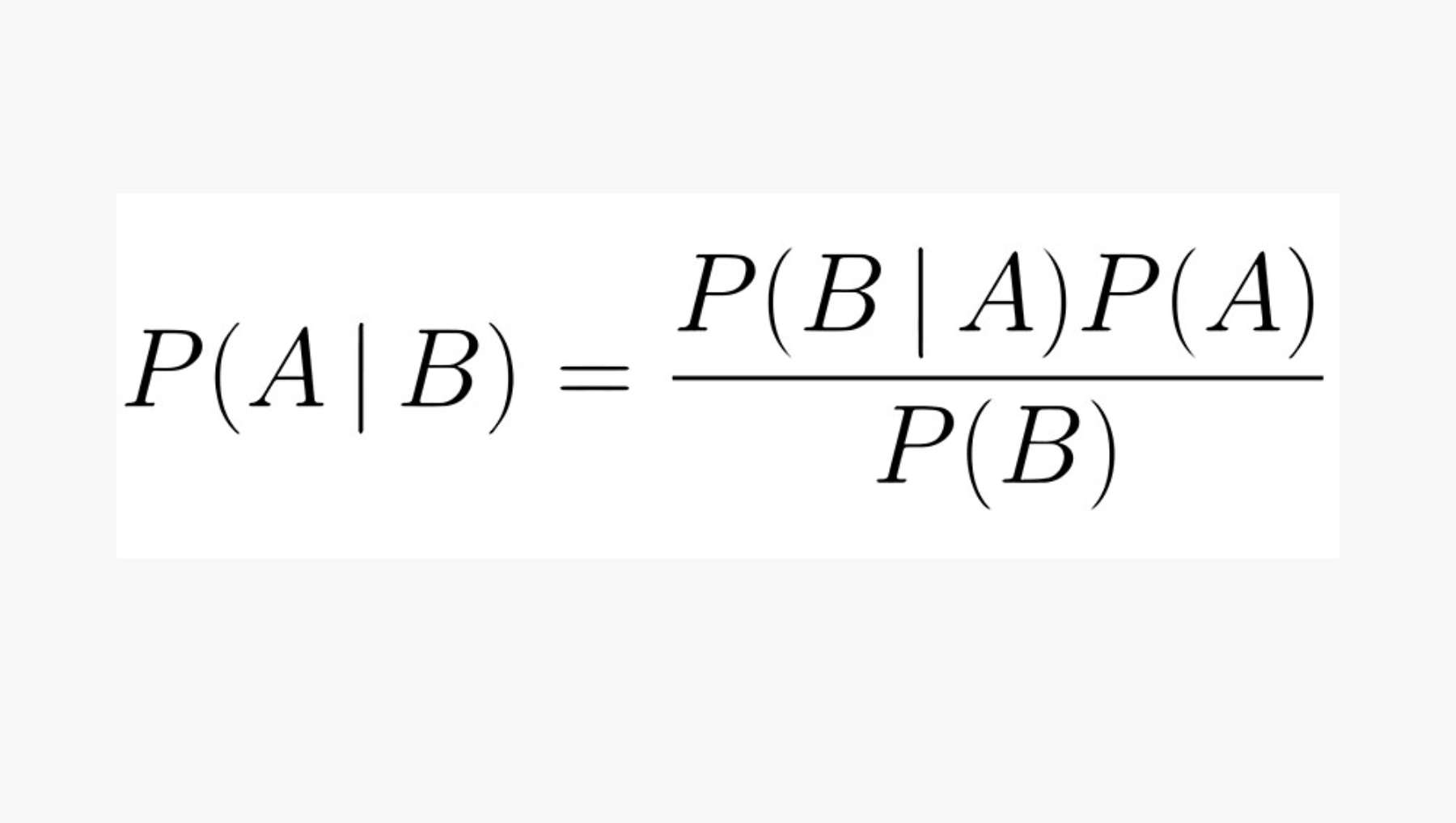
- (P(A|B)): La probabilidad posterior de la clase (A) dado el conjunto de características (B).
- (P(B|A)): La probabilidad de observar las características (B) dado que la clase es (A).
- (P(A)): La probabilidad a priori de la clase (A).
- (P(B)): La probabilidad de observar el conjunto de características (B).
Casos de Uso
Naive Bayes es muy popular en diversos casos de uso, tales como:
- Filtrado de spam: Clasificación de correos electrónicos como spam o no spam.
- Análisis de sentimiento: Clasificación de opiniones como positivas o negativas.
- Clasificación de textos: Asignación de documentos a categorías basadas en su contenido.
- Diagnóstico médico: Determinación de la probabilidad de enfermedad basada en síntomas.
Funcionamiento del Algoritmo Naive Bayes
Naive Bayes clasifica una instancia nueva calculando la probabilidad de que pertenezca a cada clase posible y eligiendo la clase con la mayor probabilidad. Utiliza el teorema de Bayes y la asunción de independencia condicional de las características.
Pasos básicos:
- Cálculo de la probabilidad a priori de cada clase:
- Esto es simplemente la proporción de datos que pertenecen a cada clase en el conjunto de entrenamiento.
- ( P(C) = Número de instancias de la clase C/ Número total de instancias)
- Cálculo de la probabilidad condicional de cada atributo dado la clase:
- Para cada característica, se calcula ( P(X_i | C) ), la probabilidad de que la característica (X_i) tome un cierto valor dado que la clase es (C).
- Aplicación del teorema de Bayes para calcular la probabilidad de que una instancia con una combinación de características pertenezca a una clase específica. Debido a la asunción de independencia condicional entre las características, esta fórmula se simplifica mucho.
- Clasificación:
- El algoritmo predice que la clase (C) con la mayor probabilidad (P(C|X_1, X_2, …, X_n)) es la clase a la que pertenece la instancia.
Ejemplo:
Supongamos que tenemos un conjunto de datos de correo electrónico con las siguientes características:
- Clase: «Spam» o «No Spam»
- Atributos:
- Si el correo contiene la palabra «Descuento»
- Si el correo contiene la palabra «Urgente»
- Si el correo tiene un archivo adjunto
El objetivo es clasificar nuevos correos electrónicos como «Spam» o «No Spam» en función de estos atributos.
Paso 1: Cálculo de las probabilidades a priori:
- ( P(Spam) = Número de correos spam/Total de correos
- ( P(No Spam) = Número de correos no spam/Total de correos
Paso 2: Cálculo de las probabilidades condicionales:
- ( P(«Descuento»|Spam) )
- ( P(«Descuento»|No Spam) )
- ( P(«Urgente»|Spam) ), etc.
Paso 3: Clasificación: Para un nuevo correo con ciertos atributos, se calcula ( P(Spam|Descuento, Urgente, Archivo adjunto) ) y ( P(No Spam|Descuento, Urgente, Archivo adjunto} ), y se selecciona la clase con mayor probabilidad.
Ejemplo en Weka
Paso 1: Cargar el Dataset
Usaremos el dataset Iris que viene incorporado en Weka. Este dataset tiene 150 instancias y 4 características (longitud y ancho del sépalo y pétalo) que se utilizan para clasificar las flores en tres especies.
Paso 2: Abrir Weka
- Abre Weka y selecciona el Explorer.
- Haz clic en Open file y selecciona el archivo
iris.arff, que está en la carpeta de datos de Weka.
Paso 3: Preprocesar los Datos
- Ve a la pestaña Preprocess para revisar las instancias y atributos.
- Asegúrate de que la clase (la especie de iris) esté correctamente asignada como atributo objetivo.
Paso 4: Seleccionar el Algoritmo Naive Bayes
- Cambia a la pestaña Classify.
- Haz clic en Choose y selecciona
Bayes > NaiveBayes.
Paso 5: Configurar el Algoritmo
- Puedes dejar los valores por defecto para este ejemplo, pero puedes explorar otras opciones del algoritmo si lo deseas.
- Asegúrate de que la opción
Use training setesté seleccionada si deseas usar el conjunto completo para el entrenamiento. Para validar el modelo, puedes seleccionarCross-validationy establecer los folds a 10.
Paso 6: Ejecutar el Algoritmo
- Haz clic en Start para ejecutar el algoritmo.
- Weka procesará los datos y mostrará los resultados en la parte inferior de la pantalla, incluyendo la precisión del modelo y una matriz de confusión.
Paso 7: Analizar Resultados
- Revisa la matriz de confusión para entender cómo el modelo ha clasificado las instancias de las diferentes especies de iris.
- Observa la precisión general, la tasa de verdaderos positivos, y otros indicadores que te darán una idea de la efectividad del modelo.
Ventajas y Desventajas
Ventajas:
- Rápido y fácil de implementar.
- Funciona bien con datos de alta dimensión.
- Requiere poco entrenamiento y puede ser muy efectivo para ciertos problemas.
Desventajas:
- La suposición de independencia puede no ser válida en muchos casos, lo que puede afectar la precisión.
- Puede tener problemas con características altamente correlacionadas.
Opciones Principales de NaiveBayes en WEKA
-
- Use kernel density estimator (
-K):- Descripción: Habilita el uso de un estimador de densidad basado en kernels para atributos numéricos. Esto permite modelar la distribución de los atributos numéricos de una manera más flexible que una simple distribución gaussiana.
- Valor por defecto: false (desactivado).
- Uso: Cuando se habilita esta opción, el modelo será más adecuado para datos que no siguen una distribución normal.
- Use supervised discretization (
-D):- Descripción: Aplica una discretización supervisada a los atributos numéricos. Esta opción discretiza los atributos continuos en intervalos antes de aplicar el algoritmo, utilizando la clase para determinar los intervalos.
- Valor por defecto: false (desactivado).
- Uso: Útil si los atributos numéricos no se ajustan bien a una distribución normal y la discretización ayuda a mejorar el rendimiento.
- Display model built (
-print):- Descripción: Muestra el modelo Naive Bayes generado, lo que incluye las probabilidades calculadas para cada atributo.
- Valor por defecto: false.
- Uso: Se utiliza para depuración o análisis para ver cómo se ha construido el modelo.
- Use Laplace correction (
-L):- Descripción: Aplica la corrección de Laplace a las estimaciones de probabilidad. Esto es útil para evitar probabilidades de 0 cuando una clase y un atributo nunca ocurren juntos en los datos de entrenamiento.
- Valor por defecto: false (desactivado).
- Uso: Útil cuando hay atributos categóricos que no tienen representación suficiente en todas las clases (previene sobreajuste).
- Use kernel density estimator (
Más información
https://www.geeksforgeeks.org/naive-bayes-classifiers/
https://es.wikipedia.org/wiki/Clasificador_bayesiano_ingenuo